Learned representation-guided diffusion models for large-image generation
Abstract
To synthesize high-fidelity samples, diffusion models typically require auxiliary data to guide the generation process. However, it is impractical to procure the painstaking patch-level annotation effort required in specialized domains like histopathology and satellite imagery; it is often performed by domain experts and involves hundreds of millions of patches. Modern-day self-supervised learning (SSL) representations encode rich semantic and visual information. In this paper, we posit that such representations are expressive enough to act as proxies to fine-grained human labels. We introduce a novel approach that trains diffusion models conditioned on embeddings from SSL. Our diffusion models successfully project these features back to high-quality histopathology and remote sensing images. In addition, we construct larger images by assembling spatially consistent patches inferred from SSL embeddings, preserving long-range dependencies. Augmenting real data by generating variations of real images improves downstream classifier accuracy for patch-level and larger, image-scale classification tasks. Our models are effective even on datasets not encountered during training, demonstrating their robustness and generalizability. Generating images from learned embeddings is agnostic to the source of the embeddings. The SSL embeddings used to generate a large image can either be extracted from a reference image, or sampled from an auxiliary model conditioned on any related modality (e.g. class labels, text, genomic data). As proof of concept, we introduce the text-to-large image synthesis paradigm where we successfully synthesize large pathology and satellite images out of text descriptions.
Model
Overview of our method.
-
(a) We train diffusion models on patches I taken from a large image conditioned on SSL embeddings (shown in the blue box).
-
(b) We present our large image generation framework in 4 steps (shown in the orange box):
- (i) We extract a set of spatially arranged embeddings from a reference image or sample them from an auxiliary model.
- (ii) For every location , we compute a conditioning vector by interpolating the spatial grid of embeddings.
- (iii) At every diffusion step, we denoise the patch using the conditioning .
- (iv) The next step is computed by averaging the denoising updates of all patches that overlap at .
Results
Qualitative results
(Top) Patches (256 × 256) from our models, and the corresponding reference real patches used to generate them. The SSLguided LDM replicates the semantics of the reference patch.
(Bottom) Large images (1024 × 1024) from our models, and the corresponding reference real images used to generate them.
We preserve the global arrangement of the semantics defined in the reference image.
FID scores
For patches, we measure FID against the real images (Vanilla FID). For large images, we follow the evaluation strategy of MultiDiffusion [3] and use FID to compare the distribution of 256 × 256 crops from synthesized large images to that of real image patches of the same size (Crop FID). We also measure FID directly between the large images and ground truth data using CLIP [35] (CLIP FID).
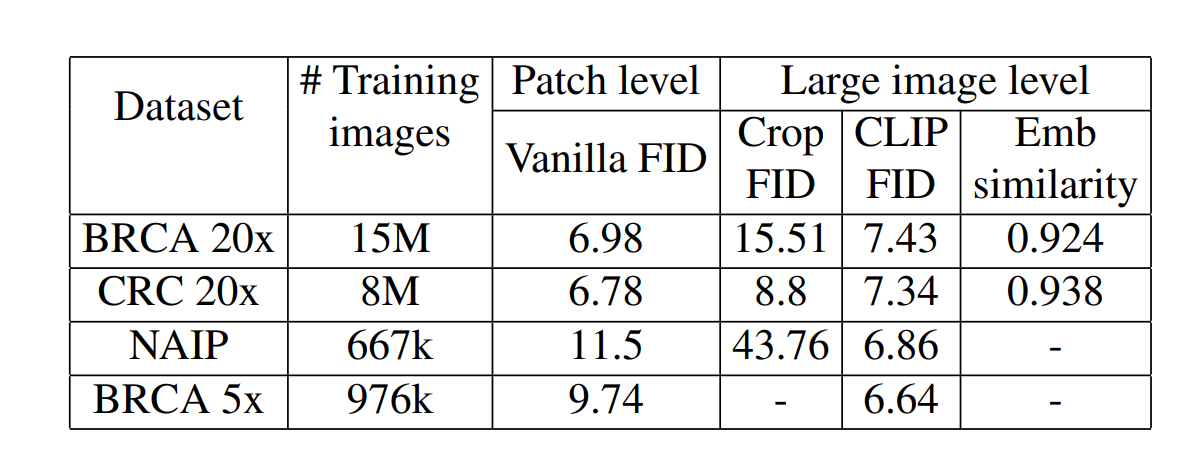
Our patch-level BRCA model is on par with SoTA [49] (7.64 at 10 ×). “CLIP FID” and “Embedding Similarity” demonstrate our large images’ realism and contextual accuracy.
Image Augmentation results

The inclusion of synthetic data consistently enhances AUC across various MIL architectures and BRCA tasks. The dataset contains 1000 real images, so “10% + synthetic” indicates training with 100 real and 100 synthetic WSIs, with the remainder used for testing.
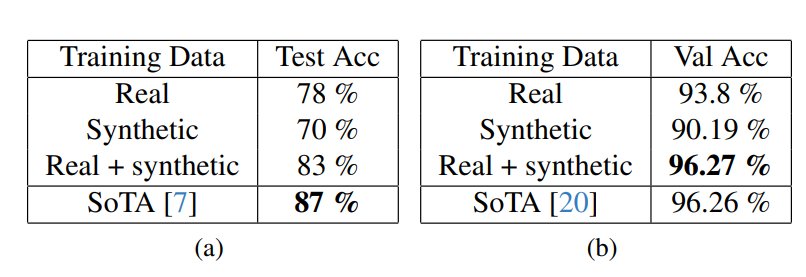
Our data augmentations provide notable improvements for the BACH (a) and CRC-VAL-HE (b) datasets. Notably, the diffusion training data does not overlap with the data of the augmented datasets.
Text-to-Large image generation
Although the grid of self-supervised embeddings z cannot be manipulated in a human-interpretable manner, we argue that it is simple to assert more control over the generated images. This control can be attained by training auxiliary models that translate higher-level conditioning signals, such as text captions , to learned patch representations .
We train an auxilliary diffusion model that learns to map text conditions (using pathology Vision-Language models) to a grid of self-supervised embeddings and showcase examples of text-to-large image generation.
Citation
@inproceedings{graikos2024learned,
title={Learned representation-guided diffusion models for large-image generation},
author={Graikos, Alexandros and Yellapragada, Srikar and Le, Minh-Quan and Kapse, Saarthak and Prasanna, Prateek and Saltz, Joel and Samaras, Dimitris},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8532--8542},
year={2024}
}