ZoomLDM: Latent Diffusion Model for multi-scale conditional histopathology image generation
Abstract
Diffusion models have revolutionized image generation, yet several challenges restrict their application in digital pathology. Existing approaches struggle with precise control over the appearance of image patches, are typically confined to generating images at a single magnification level, and face limitations due to the lack of large annotated datasets which have been essential to the success of diffusion models in the natural image domain. Self-supervised encoders have emerged as a viable workaround for the annotation deficit, yet their effective application across varying magnifications presents its own set of challenges. We present ZoomLDM, a latent diffusion model tailored for generating histopathology images across a spectrum of magnifications. Central to our approach is a novel magnification-aware conditioning mechanism, that leverages a patch summarization CNN, jointly trained with the diffusion model. This CNN processes self-supervised embeddings, retaining vital information and enabling controllable image generation. ZoomLDM achieves state-of-the-art image generation quality, especially in lower magnifications where there is limited data availability. Furthermore, we introduce a second model to generate the embeddings consumed by the conditioning mechanism, eliminating the dependency on recycling existing embeddings and facilitating the generation of novel images.
Model
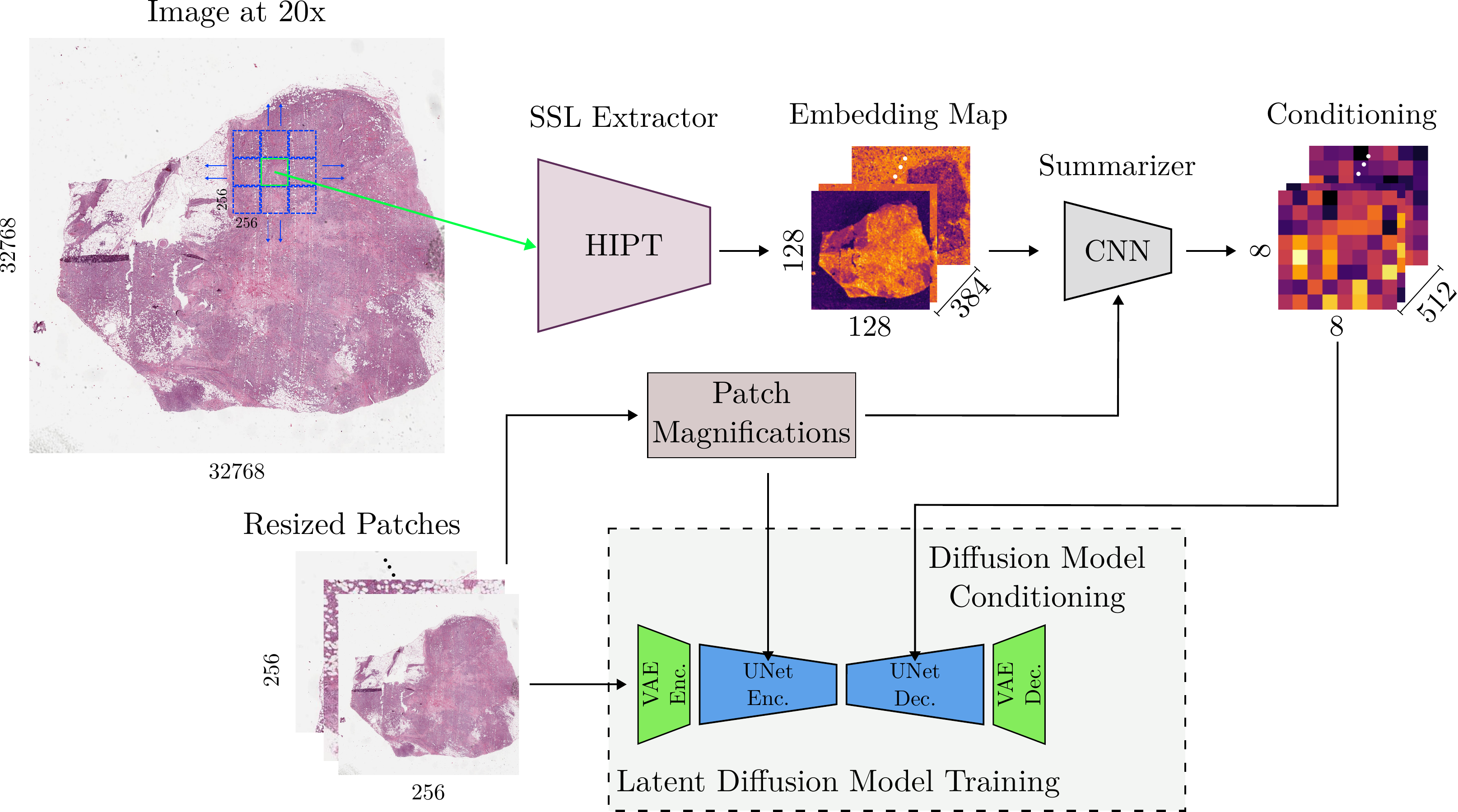
Overview of our method.
- We extract patches and the corresponding regions across all magnifications.
- Following this, we apply HIPT on the region in a patch-wise manner to obtain an embedding matrix.
- Our CNN processes this matrix, producing an output vector of size , which then conditions the diffusion model.
- The CNN is designed to be magnification-aware, enabling it to identify the appropriate level of detail required at different scales.
Results
Qualitative results
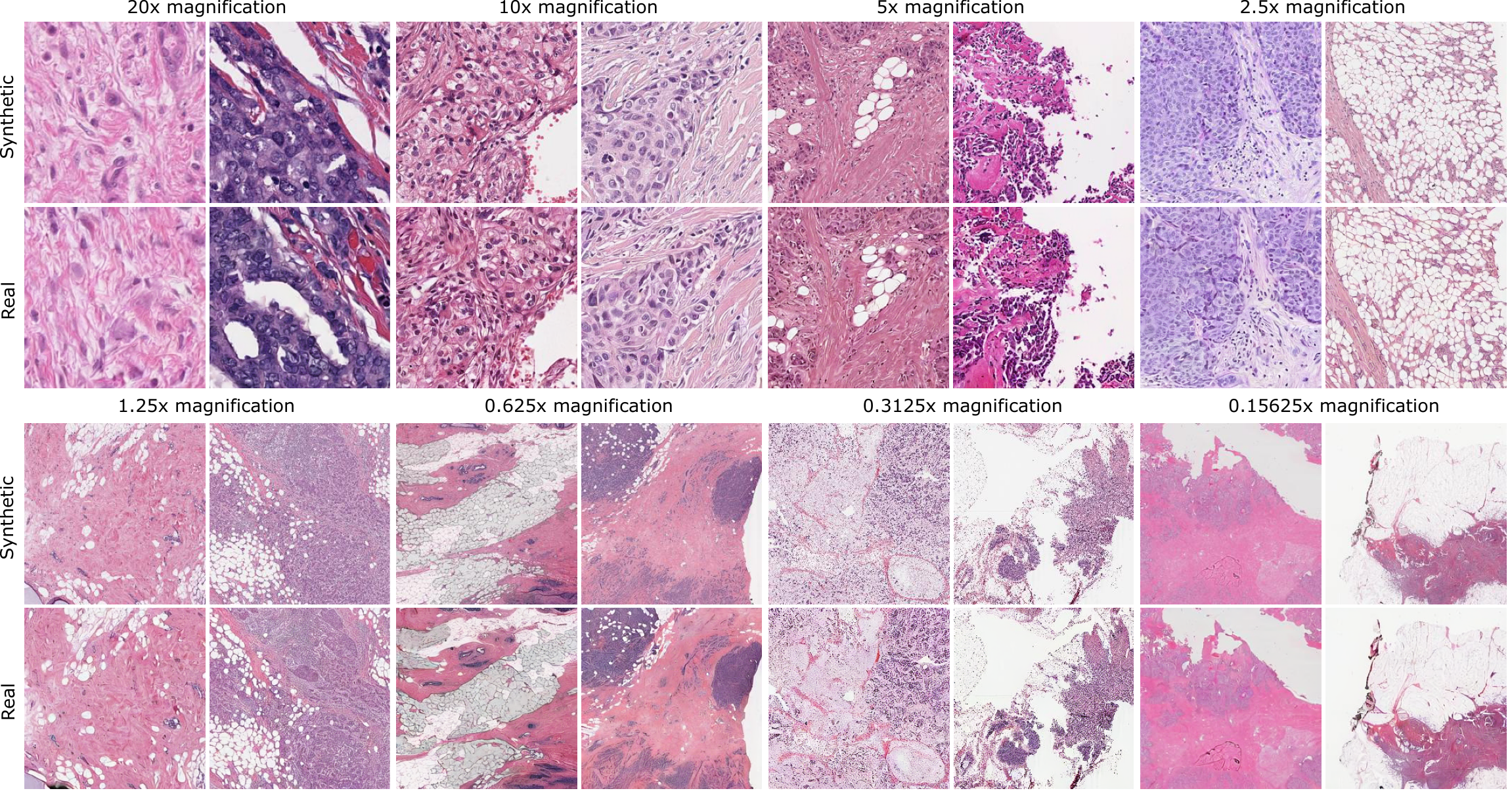
Synthetic patches ( pixel) from ZoomLDM, juxtaposed with the reference (real) images used to generate them.
Across all magnifications, ZoomLDM demonstrates consistent preservation semantic features of the reference patches.
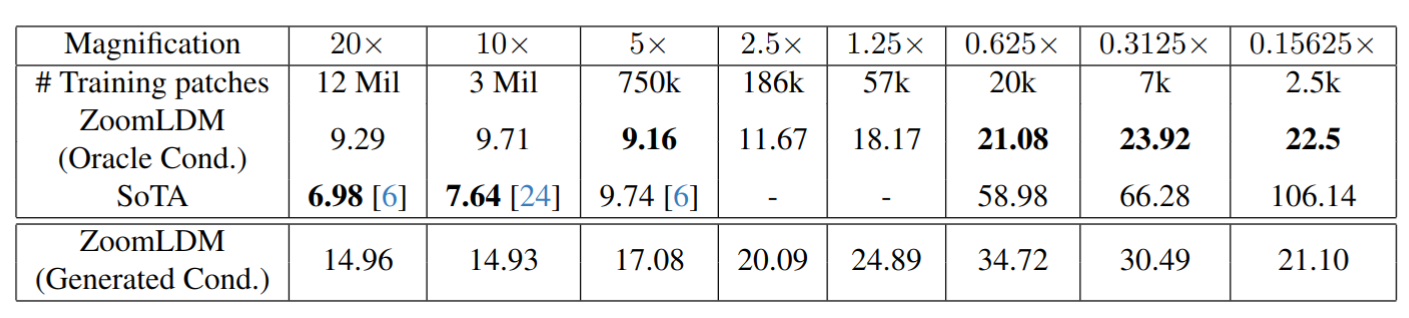
FID scores
FID of patches generated from ZoomLDM across different magnifications, compared with single magnification models. Our model achieves comparable performance to SoTA at higher magnifications and starts to outperform at magnifications lower than . By Oracle Cond. we denote generating images using ground truth conditions extracted from the training set. Generated Cond. refers to synthesizing images from conditions sampled from our EDM.
Novel image synthesis
We evaluate the EDM by hierarchically synthesizing 10,000 patches at all magnifications; we first sample an embedding from the trained model and then we synthesize the corresponding image. As shown in the above table, the generated embedding-conditioned model FID (Generated Cond.) drops when compared to the ZoomLDM that has access to the training set (Oracle Cond.). We showcase novel images in the supplementary material.
Zooming in
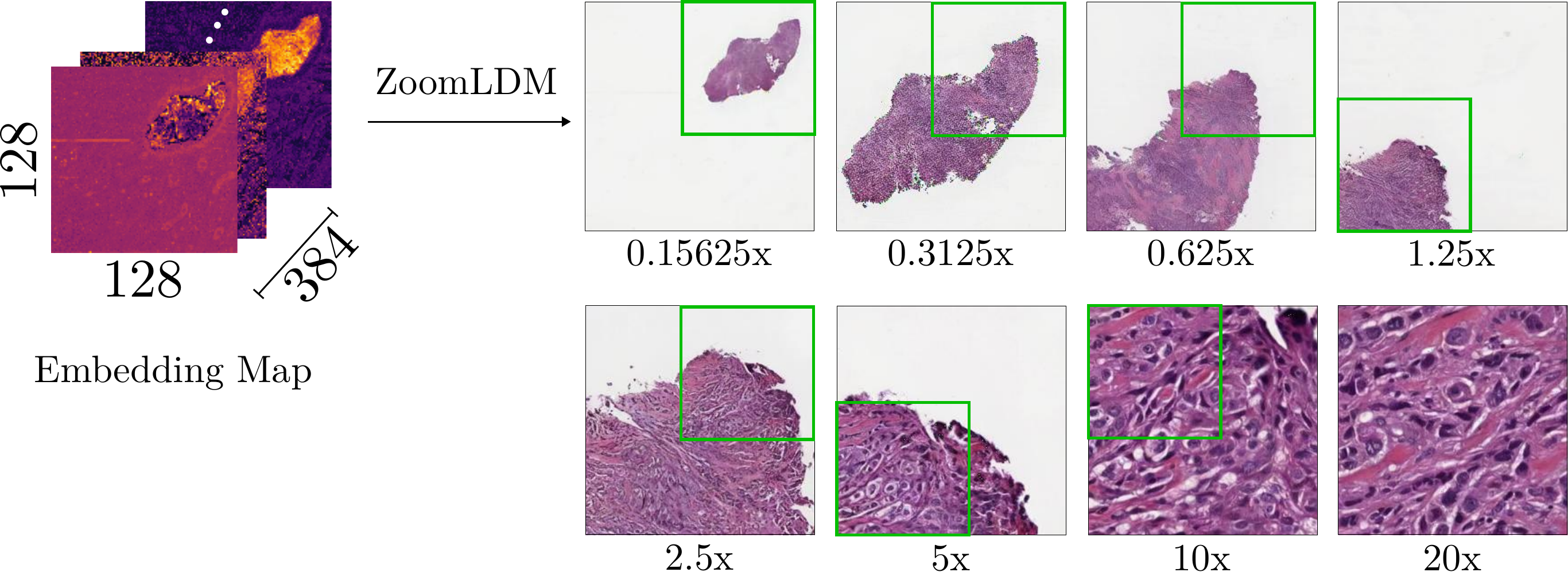
We demonstrate a decompression pipeline, where we re-synthesize patches at all magnifications of the image, stored as SSL embeddings. The decompression is performed by initializing the diffusion process at a single magnification from an intermediate timestep (), using an upsampled version of the previous magnification patch.